We help professionals, small businesses, bloggers, extra income seekers to reach an interested audience, build trust and convert their skills to income!
Here is how you can create a desktop shortcut for your chrome user profile. If you have different gmail ids this will help you quickly access different g-drive or gmail accounts in separate windows on chrome.
Click the three dots on the top right of the chrome window (The tool tip would read customize and control chrome)
Scroll down and click on settings
Click on customize your chrome profile
Scroll down to “Create desktop shortcut” and enable it.
We discussed Google’s announcement of passage and sub-topic indexing and how to optimise for it. In the same announcement, they also mentioned they now can understand different segments of a video and return specific time stamps of relevant content to the user. How did Google get to this amazing stage? How did it train its AI to achieve this level of granularity? A discussion.
We will not discuss the technical aspects of the AI algorithm. Our focus here would be how Google got to this stage of discerning content. The first step is data and as we well know, we are the source!
Let us consider just a handful of example to appreciate how granular index was achieved. First, what is granular indexing? This just refers to Google’s ability to tell site A and site B apart; tell video A and video B apart; passage one and passage 10 in the same article apart; Time state 3:20 and 4:50 in the same video apart and so on.
1 The disavow tool
The first example I can think of the disavow tool in Google search console. What was once an integral part of the search console, (when it was called Google Webmaster tool prior May 2015) has now been moved to obscurity because of AI capabilities.
If we suscept a spammy or suspicious website has linked to our site, we can inform google about this. We could upload a set of all such spammy sites in a text file. Google happily got this information from tens of thousands of Webmaster for several years and fed it to their AI algorithm.
With access to so much data, they could tinker their AI code to near perfection and spot a good site from a spammy site. At that point they happily told webmasters manual disavowal was no longer necessary (although still available) and “AI would take care of it”
The granular indexing formula: Get data from users, use it as input, perfect the code and let it loose on the web.
This Twitter poll says it all!
How many of you have disavowed links in GSC this year?
The data they got from searchers and users was not enough! Google actually employed thousands of quality raters with extensive guidelines to test how the AI was coughing up results. The raters were trained to identify sites with authentic information especially in YMYL (your money or your life) niches like health and finance.
For example, if a website was claiming that the Earth was flat, it would never feature in scientific searches; if a website claims (to borrow an example from the actual guideline) that carrots can cure cancer, the site could even be removed entirely from the index.
Quality rates are used to evaluate author profiles, site privacy policy, conflict of interest etc. Once they got enough information to create a search pattern Google made an extraordinary announcement in late 2019.
3 Removing Manual Submission to Google News
This announcement shock those who wanted to “get into” Google News – a huge source of traffic and authority. Previously site owners had to apply for inclusion into Google News. Now the AI would decide which is a news site and which is not. In fact, the AI is so good it can differentiate between article A and B from the same site – A could feature in Google News and B will not. Here are two examples of this.
Screenshot of freefincal articles appearing on Google NewsBrief Google News appearance of freefincal articles as seen from search console screenshot
A search for “freefincal” on the Google News tab occasionally shows actual articles instead of references to freefincal or its author in news sites already on Google News. This is a precise example of granular indexing.
Other examples
Google Maps understands the nature of a business from its reviews.
Youtube now can understand comments and offers a choice of automated responses to the channel owner.
They study likes; dislikes and comments to understand what videos would keep viewers engaged on YouTube longer
Gmail can now understand what emails are about and offer automated responses and autocomplete
Passage indexing; video key moment indexing, sub-topic indexing are all part of this progression arc. The future is existing but also scary. This is the reason why they say “data is the new oil”. Google and Facebook stocks holders are laughing themselves to check on their demat accounts!
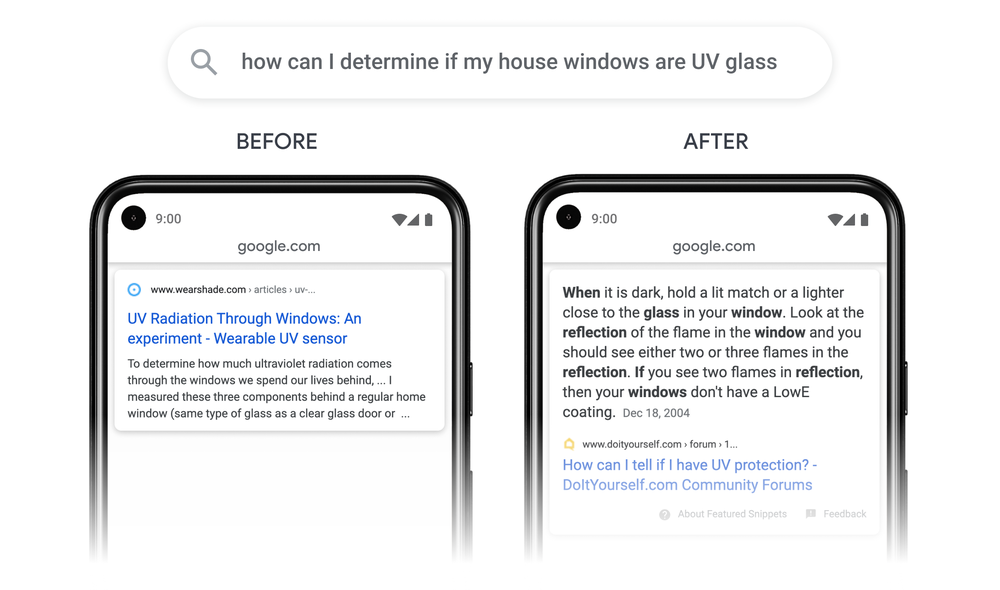
Google announced on Oct 15th 2020 that it can now rank specific passages (paragraphs) and sub-topics of articles and present them for specific queries. What does this mean and how do we optimise for “Passage SEO”? A discussion.
Every piece of content we produce should try and solve a question or problem our readers may have. If we approach every content with this mindset most of our SEO effort is already accomplished.
It is well known that articles with questions in the titles do well. For example: “Nifty vs Sensex*: Which should I choose for passive investing?” This is a common question index investors have and the title makes it clear what entities are being compared and why. * The Nifty and Sensex are Indian stock market indices.
Optimising for Sub-topics
If the article title addresses one question a reader is likely to have, we can make an article more useful by adding additional and associated questions as sub-topics (with H2 headings).
For example, a reader looking to understand the difference between the Nifty and Sensex would first look for a basic definition of these; how they are constructed etc.
As the reader goes through your text, imagine what additional questions would arise:
How different were their returns in the last five years?
How do the top ten stocks differ in these? Has there ever been a time when the compositions were significantly different?
Which has more day to day price fluctuations?
Which has more concentration risk?
These are natural questions that crop up as the reader progresses through the article. Addressing these questions without worrying “optimising for a specific keyword” is the best way we can be helpful to our readers and automatically this is the best way to ensure the content related to each sub-topics is showcased for specific queries by Google.
Passage SEO
The logic here is the same. One passage (paragraph) should naturally and logically follow another. The image shown below is a screenshot from Google’s announcement (link in the caption)
For example, as you address the differences between the Nifty and Sensex, a reader might wonder, “what about the Nifty Next 50, Nifty 100?”. These natural questions can simply be addressed as a paragraph as shown in the example below.
Concentration risk in the Nifty 100? The Nifty 100 which includes an additional 50 stocks has relatively lower concentration risk. For example …..
So when someone searches for Nifty 100 composition or Nifty 100 concentration risk, the above section can be directly shown in the featured snippet (with the relevant link). Even though we mentioned Nifty 100 only in passing and our article was about Sensex and Nifty, Google could showcase the relevant passage from an article instead of a Nifty 100 specific article.
Summary
To optimise for sub-topic ranking and passage ranking it is important we think like a reader who has no clue about the topic of our article.
The logical sequence of how you would explain the subject to a reader should shine through in the article as sub-topics (with an H2 sub-heading if necessary) and as clear passages.
Each passage should convey one distinct message but should also be interconnected to the narrative so that it does not stand out.
The natural way to do this better is to become an expert in our subject matter by having a clear understanding of “what our readers want?”. Our course “How to get people to pay for your skills” aka “Earn from Skills” teaches you how to do this step by step with over ten hours of video content. Learn more about the course, and watch the first video for free: How to build a second income source that will last a lifetime
Paul Bakaus, product manager, software engineer and developer advocate leading Web Creator Relations, AMP Ecosystem Relations at Google, announced on Oct 6th in the Google Web Creators YouTube channel that web stories will now be featured in the Google Discover feed for audiences in the USA, India and Brazil.
This is a screenshot of the feature as on 14:00 hours 7th Oct 2020.
screenshot of Web Stories on Google Discover
For the uninitiated, a web story is previously known as ‘AMP story’ is a visual way to tell a story. It behaves like a mini “PowerPoint presentation” that you can experience from the Google Discover feed. It has slide transition and animation possibilities. You can read more about this on the Google stories page
Here are some single page web stories created by freefincal.com
Once you become a member of the”Earn from Skills” Facebook group, you can become a reseller of the course for a 30% commission. To do this, you need an Instamojo account. You can set one up with a valid Pan no and bank account. For monthly payouts greater than Rs. 10,000, you will need to verify your KYC.
This means uploading your Pan card photo and bank statement photo. I strongly recommend that you do this. You could then sign up as reseller via this link. This way you offer a 30% discount to anyone “buying though you” and you would get a 30% commission on the sale. After taking away Rs. 28-30 as Instamojo fees, you should be able to make Rs. 1000 per sale.
The advantage with this arrangement is, a buyer if they go through you, they get a 30% discount (if they go via freefincal they will pay the full fee of Rs. 5000) and you get a 30% commission on it. So the advantage is 50-50. Further instructions on how to resell the course without misrepresentation are presented in this video
Our new course – How to get people to pay for your skills is now open! In less than a day, more than a 100 from our community have signed up for lifetime membership in our exclusive Facebook group by paying a one-time early-bird fee of Rs. 2000. Thank you for your support!
Who is this course for: This is for anyone looking to earn extra income (aka side hustle) or passive income; anyone who wants to start a blog or YouTube channel or build a social media following; for entrepreneurs; small business owners; anyone who would like to build a business by showcasing their expertise, for example, financial advisors, insurance advisors, software consultants, writers, just about any service that requires an online presence
Watch the first lecture for free below! If you wish to know more about me and my experience and expertise in this area, first check out this video:
The first lecture of the course is here:
Course Objective: A complete framework to build online visibility with your skills; Create a community of readers and viewers based on expertise and trust and generate an income that will gradually grow to become significant.
Course Format: Videos (20-30 min duration) in a Facebook Group.
(Each number will correspond to one video approximately)
1: Overview of objective and what will be covered. (This will be free for all). Watch this part above.
2: Step Zero: What is your goal? How to define success and making money.
Step one: What will make you truly happy? Some members may already know what they want to do (eg sell mattresses or become a financial advisor) and some members may still be searching for what topic they would like to work on. We shall keep this mind as we discuss.
What is a ‘solution gap’? How this will decide your online presence, trust, following and income.
3: Steps two-four: Choosing a topic to work with. Choosing a format. How to find problems in a particular topic that you can address
4: Basics of setting up a website – why it is indispensable. Different ways to showcase your competence. Pros and cons of each method.
5: Overview of making money online. Pros and cons of each method
6: Deciding your game plan (whether you are sure about what to do or not!). Choosing a monetization strategy that is right for you.
7,8: Website site walk-through: From buying a domain, hosting to setting it up before you write your first blog post.
9: Social Media Account Set up. How to develop a following without trolling others
10: Why and how to develop an email list
11: Setting up a Google My Business Page and how to maintain it
12:Â Youtube: How to use it, how not to, how to get started and what to expect.
13: Automating tasks: Tips and Tools
14: How to always have ten ideas to create content with
15: How to let potential products and services evolve from content and community
16: Active vs Passive Income: What Should You use. What does passive really mean?
17: When to start selling products; How to ensure consistent sales?
18: How to launch a product? When to advertise and when not to! What to advertise and what not to!
19: How to stay updated on the latest developments in your area and online visibility. How to stay ahead of the curve by not being afraid to experiment.
20: How to exploit features specific to mobile to showcase our content to new audiences
21:Â A look at all the tools I use strategies
22: Plus other topics that you think would help. Send an email to pattu “at” freefincal.com if you have suggestions.
Features of the course
The course will mention popular products/services you should not waste money on. The total cost of this alone will be 3-5 times the full price of the course.
All products mentioned in the course are those I use. You can get to see methods and plugins I use.
Once the early bird discount period is over, the course fee will be Rs. 5000. Interested members can resell the course for a 30% commission. This means a single sale would offset 75% of the early bird fee of Rs. 2000
If you a professional consultant, even the full fee will be a fraction of what you charge from a single client.
Essentially what I have learned over the last eight years will be part of the course.
There is a lot of nonsense peddled around in the marketing and SEO worlds. The course will aim to dispel much of this.
“How to get people to pay for your skills” is a new course by Dr. M. Pattabiraman, founder and editor of freefincal.com. It is meant for entrepreneurs, small business owners, professionals like financial advisors, insurance advisors, fitness coaches etc. to showcase their skills online and generate a steady stream of clients.
It can also be used by bloggers, vloggers or anyone looking for a secondary source of income (side-hustle) or a passive income source. While those with expertise in an area (professional)
Course Objective: A complete framework to build online visibility with your skills; Create a community of readers and viewers based on expertise and trust and generate an income that will gradually grow to become significant.
Course Format: Videos (20-30 min duration) in a Facebook Group.
Course Fee: Full Price Rs. 5000. Early Bird Discount Rs. 2000. Sign up for the early bird discount via this form. The fee is deliberately kept low to enable young earners and college students to participate.
[jetpack_subscription_form title=”Get our free tips on income generation and online visibility in your inbox!” subscribe_text=”No spam! Only unbiased, unique insights” subscribe_button=”Sign Me Up!” show_subscribers_total=”0″]